What is Sysrev?
Sysrev is the first open access document review platform. Users create projects where they upload articles, define review tasks, and recruit a team. The team then performs the review tasks on the uploaded articles. Sysrev automates these tasks by building new machine learning models once every 24 hours.
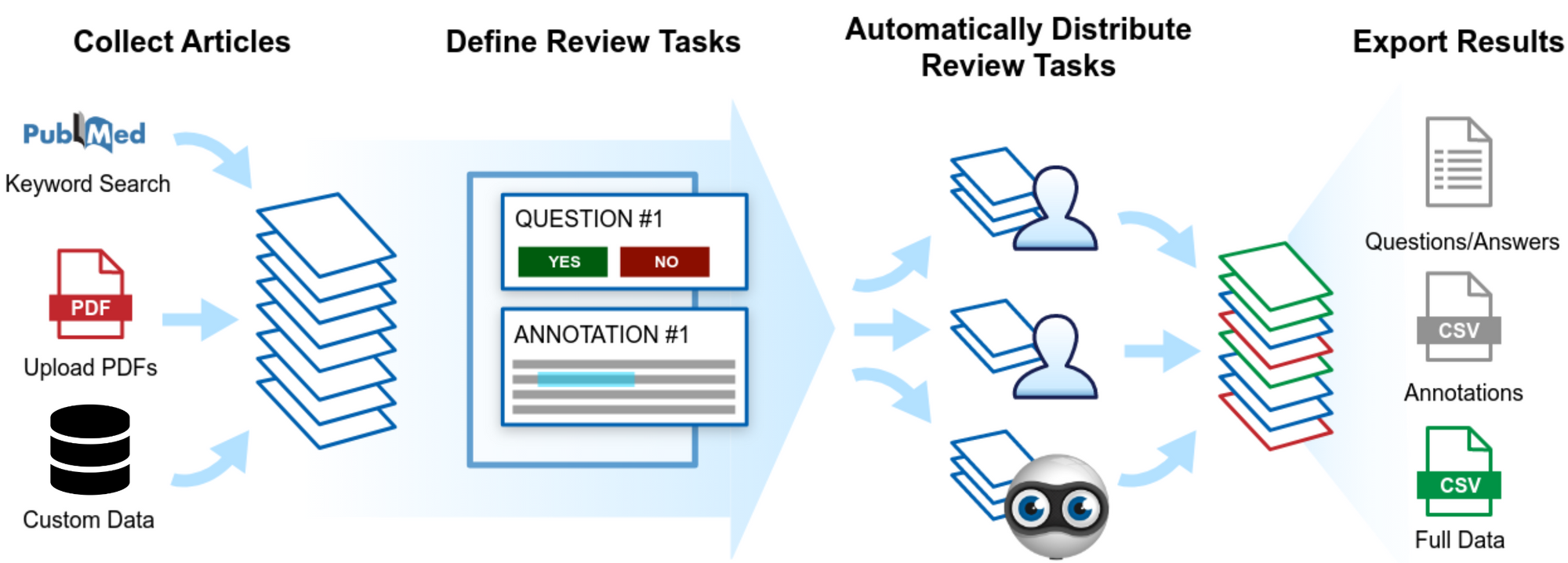
Sysrev review tasks are called 'labels', and they define some kind of structured data that will be extracted from each document in the review. These could be tasks like "should this article be included in my review?" or "what species did this article discuss?". Sysrev supports a variety of label types from simple boolean and categorical labels to complex tabular extractions and many more.
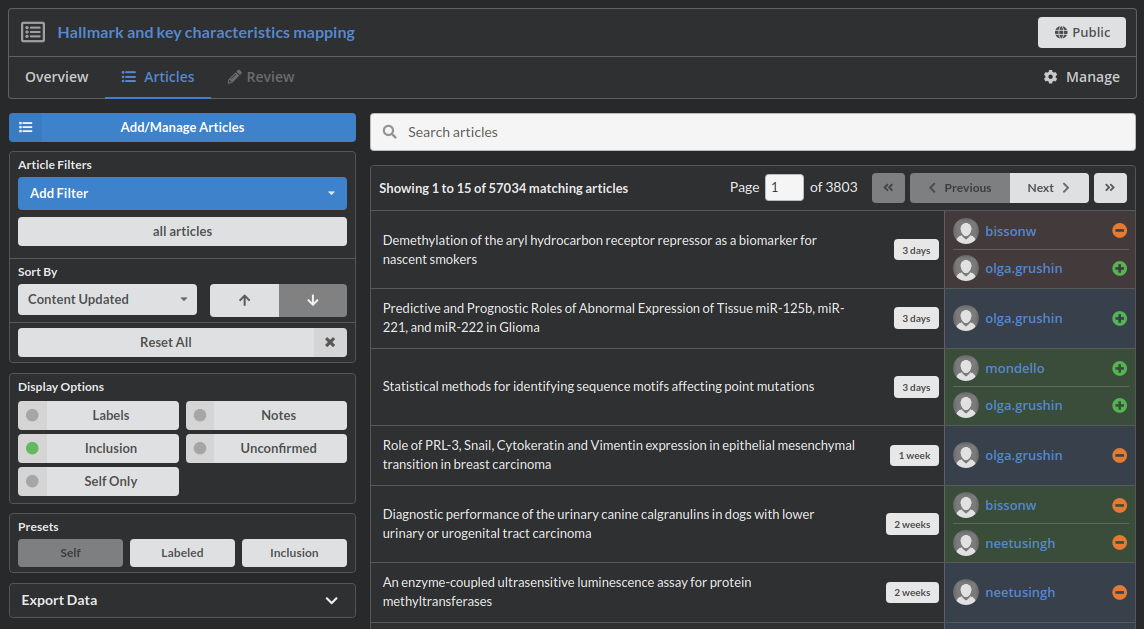
Every time a reviewer reviews an article, that action is recorded and accessible on the given project page. Each sysrev project is given it's own url, and many public projects can be accessed by anybody. For example, you can view every review decision made in the sysrev mangiferin project at sysrev.com/p/21696/articles. Public projects at sysrev allow users to easily share their work. This makes reviews more trustworthy and re-usable. Learn more at fair-review and proof of review.
To get started, sign up at sysrev.com. Read our getting started post to learn how to create a sysrev in just a 2-3 minutes.