Literature and Data Review with Sysrev
Sysrev is a powerful, collaborative platform for document review. Whether conducting a literature review or curating data from machine learning, Sysrev offers a versatile feature set to optimize even the most complex data extraction tasks.
Sysrev is an intelligent, collaborative platform for document review and data extraction. It is a great tool for Literature Reviews & Data Curation.
Literature reviews are summaries of research. They identify the relevant publications for a research question and attempt to generalize methods and outcomes, and gaps in research. Literature reviews are an essential tool for research, regulatory assessment and landscape analyses. One particularly rigorous form or review is systematic review.
If you are interested in systematic reviews "Supporting COVID Research" details how an international team used Sysrev (for free!) for three phases of their review (Screen, Extract, Assess) for A Systematic Review of COVID-19 and Kidney Transplantation.
Another type of literature review is called a narrative review, in which the aim of the review is to simply gain a macro-level understanding of the subject matter. For these applications, Sysrev has machine-learning capabilities to help optimize the process.
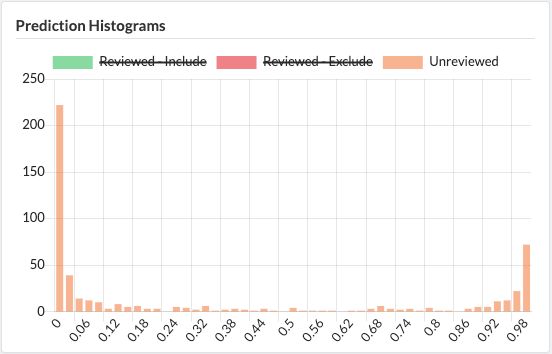
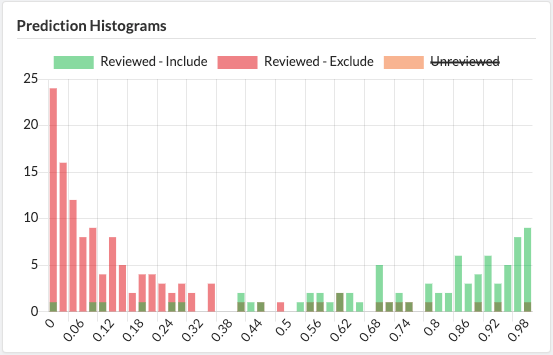
In our narrative review of Mangiferin, we utilized Sysrev's machine learning to save time on the screening process. After manually reviewing 206/725 articles, we used Sysrev Inclusion Predictor Model to screen the remaining articles. You can learn more about this process in our blog post "Mangiferin Managed Review"
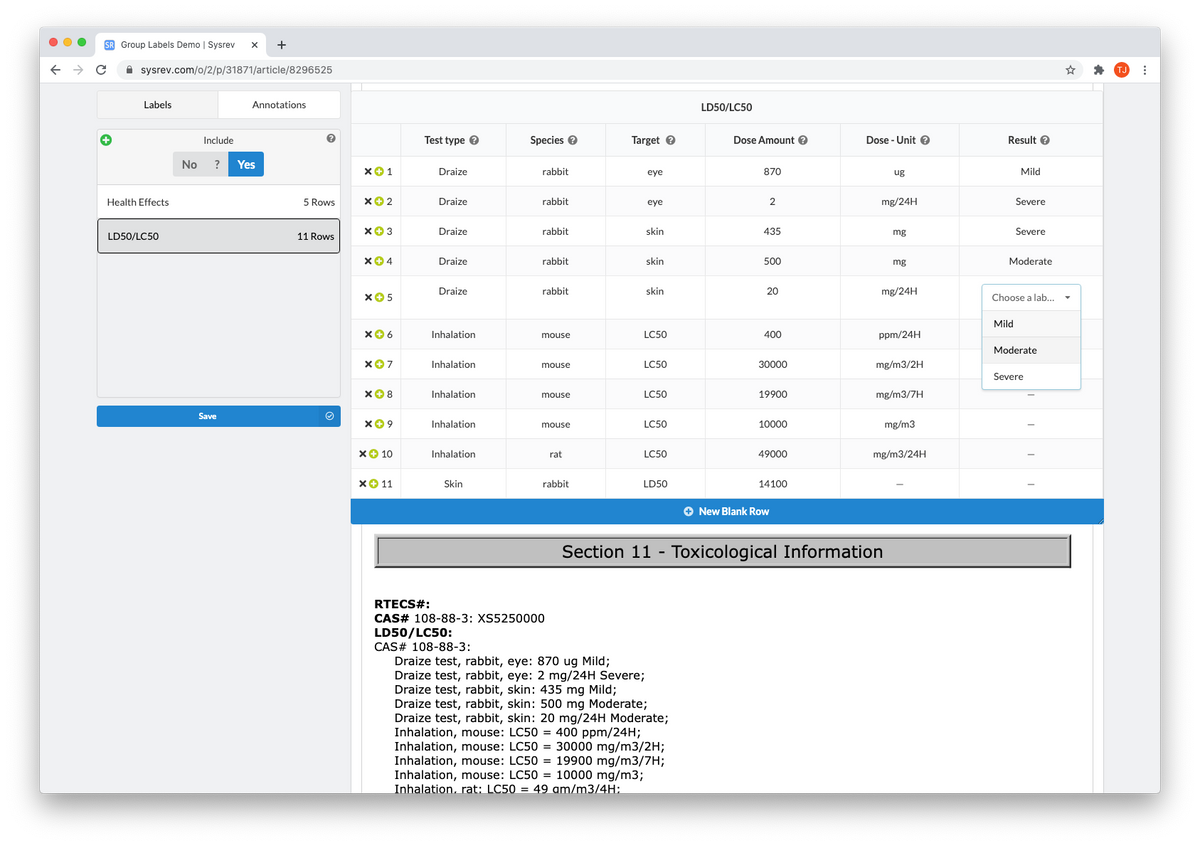
Data curation is when data is extracted for the purpose of building a standardized dataset, often for machine learning. We actually built Sysrev version 0.1 to help curate training data for our own predictive models. In the time since, we have added a number of features specifically for complex data extraction.
One of the biggest problems in data extraction tasks is simply not knowing how much or what types of data are in a given document. As an example, imagine you are interested extracting chemical toxicity testing data from scientific publications. How does one capture the variations between dose, species, and effect? Perhaps the salmonella responded at 10 micrograms but the e. coli responded at 15 micrograms. The below video showcases many of Sysrev's data curation features. The whole series is at youtube.com/@SysRev
Sysrev is a powerful platform built on simple, versatile tools. Our aim is to allow ours users to review any document and extract any data. If you have a literature review or data extraction project, or even an idea to make Sysrev even better, please feel free to drop us a line at info@sysrev.com.