Extracting Data from Partially Structured Sources
Partially structured data sources are goldmines of information, yet consist of large documents that are cumbersome to review. This post explores how the hierarchy of the document can be leveraged for more efficient data extraction.
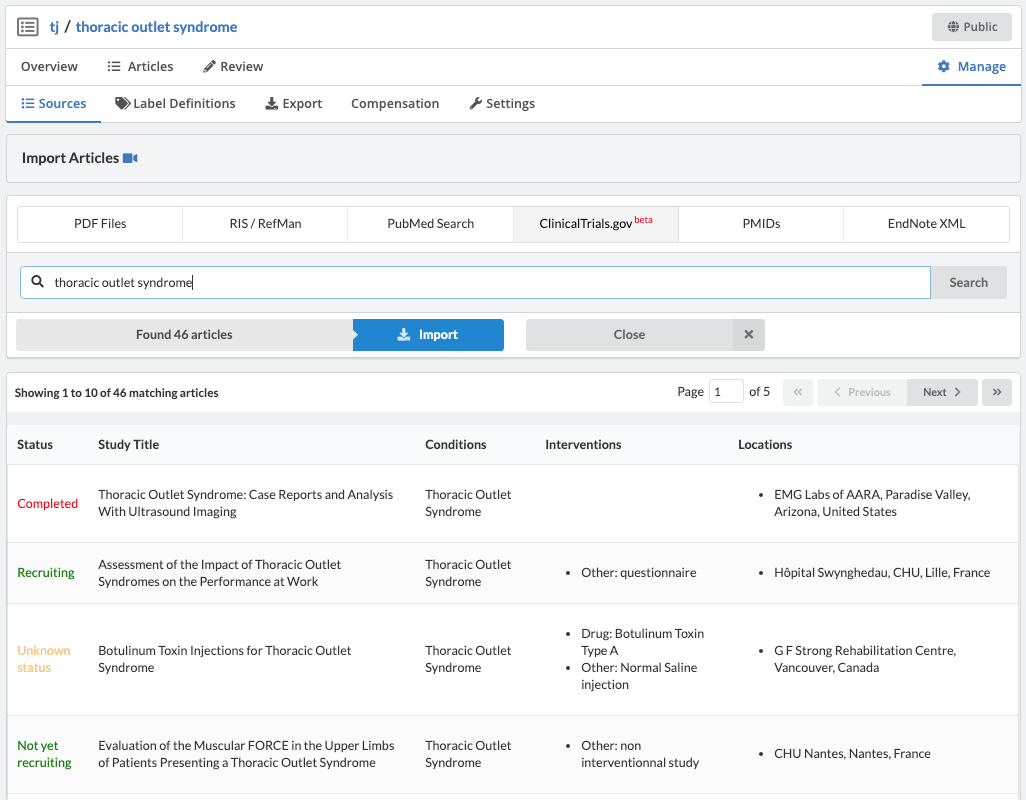
"Partially structured data sources are goldmines of information, yet consist of large documents that are cumbersome to review."
For the modern organization, data determines success. The ability to aggregate data and utilize advanced statistics to illuminate insight is crucial to any efficient operation. Every discipline and vertical, from marketing to HR to real estate, benefits from data science.
Before data can be analyzed, it must be curated. Careful curation is crucial to the success of any analytical undertaking as the degree to which the data is standardized largely dictates the type of analysis that can be performed.
Sometimes, data is easy to find and comes pre-curated - formatted into a .csv hosted at a permanent location on the web just waiting to be downloaded.
Other times, data is harder to find. In academia, data is spread across disjointed publications, each consisting of multiple pages of prose, tables, and graphs. The difficulty in aggregating data in a reproducible way led to the practice of systematic reviews. Sysrev was originally developed to optimize the process of multi-document review and data extraction.
Finally, there are large collections of Partially Structured Data. These data sources are goldmines of information, yet consist of large documents that are cumbersome to review. As an example, let's take a look at ClinicalTrials.gov.
As the name implies, ClinicalTrials.gov is the U.S. National Library of Medicine's repository of medical trials. A lot of research, both academic and commercial, is built on data extracted from these trials.
Partially Structured Data Source
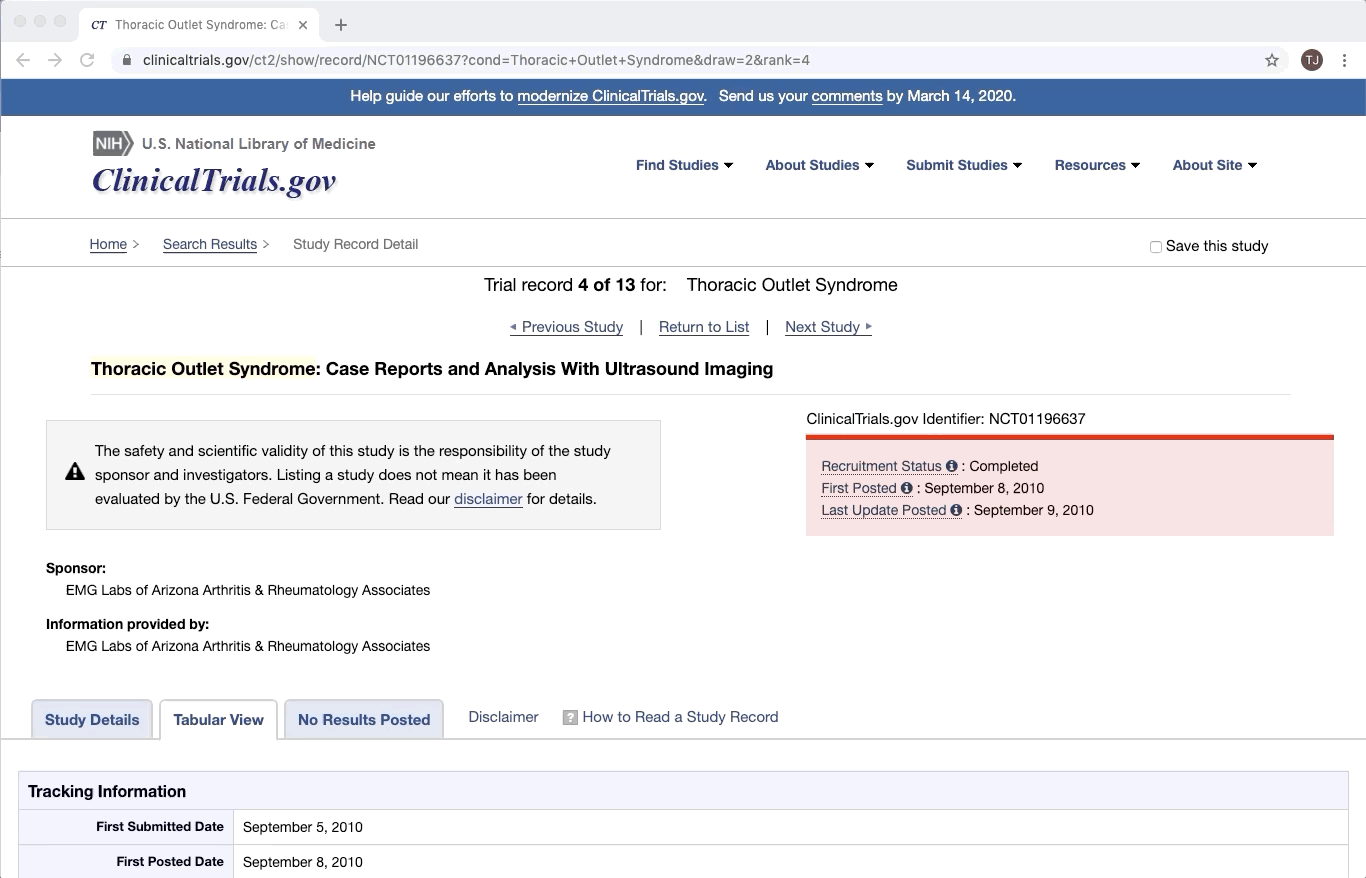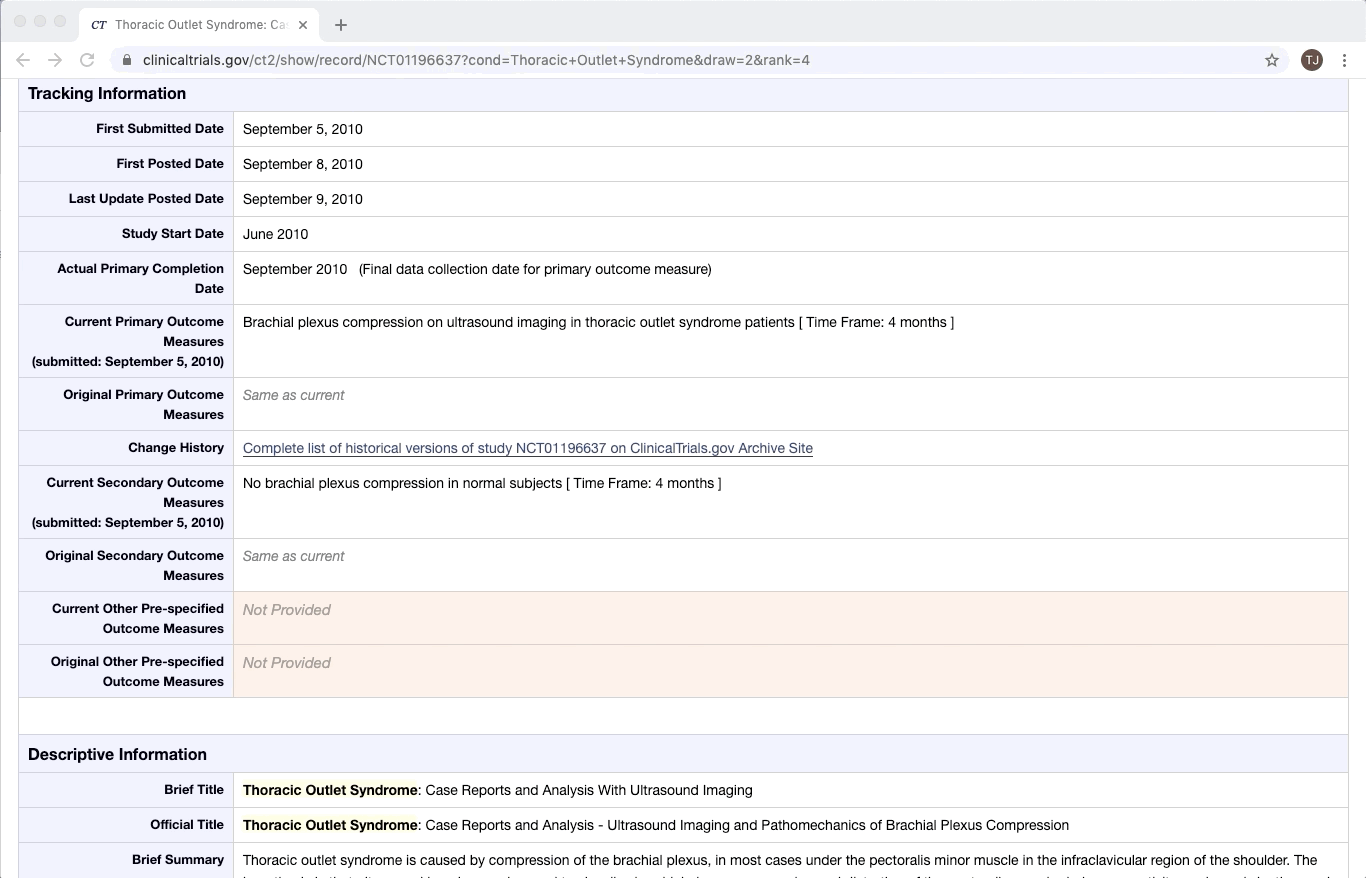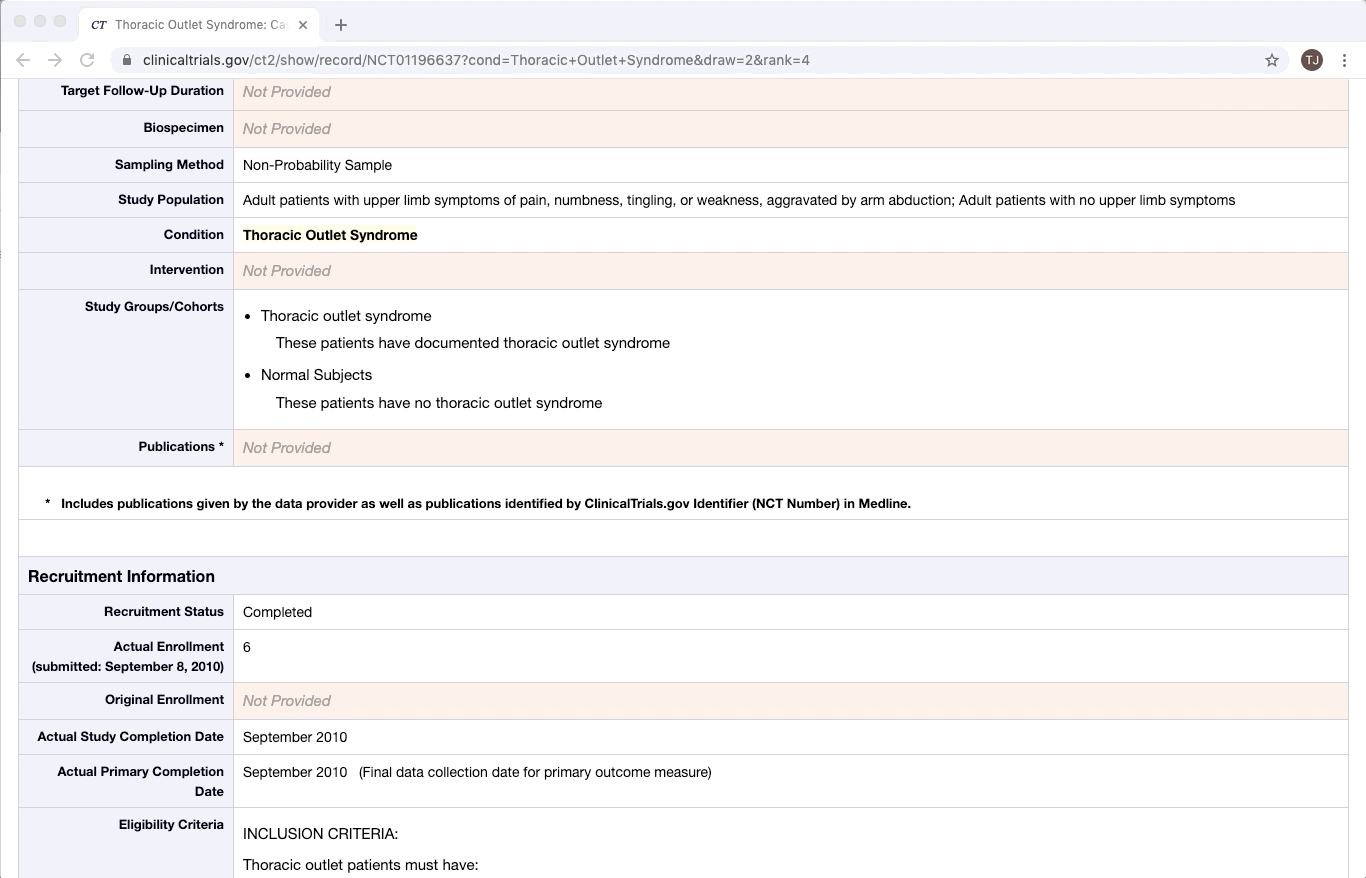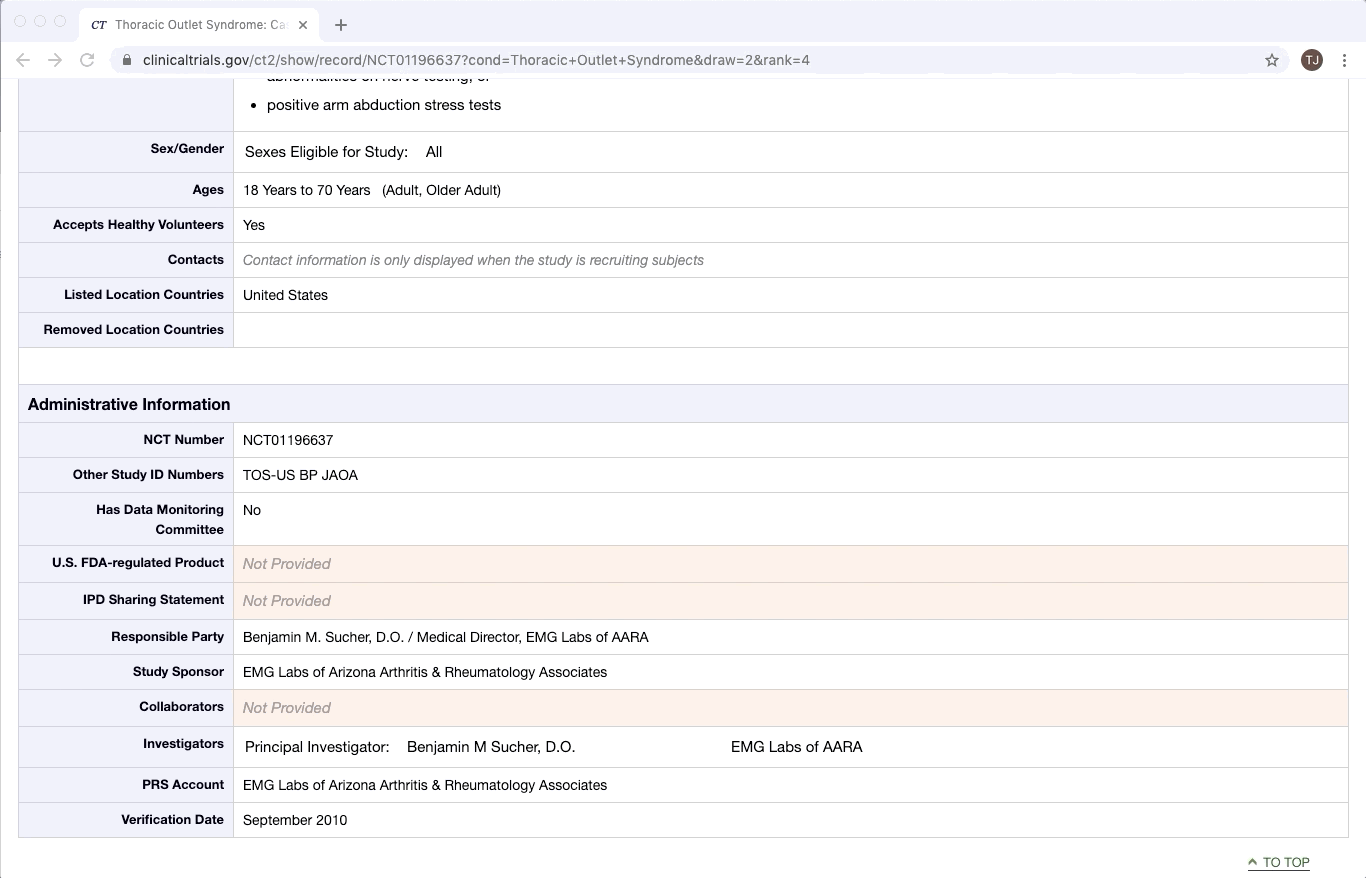
ClinicalTrials.gov is an excellent example of partially structured data. There are specific categories of data that exist in every trial on ClinicalTrials.gov. Yet within a given category, there is a lot of variation between documents. This is especially true of the more qualitative or complex fields e.g. Brief Summary, Detailed Description, and Eligibility Criteria.
While certain fields can be mined with machine learning, the more dense fields (which tend to be the fields of interest) still require human extraction.
ClinicalTrials.gov has an API for querying and downloading trials. Via this API, Sysrev has a native clinicaltrials.gov integration which allows users to search for, import, and review trials - all within the Sysrev platform.
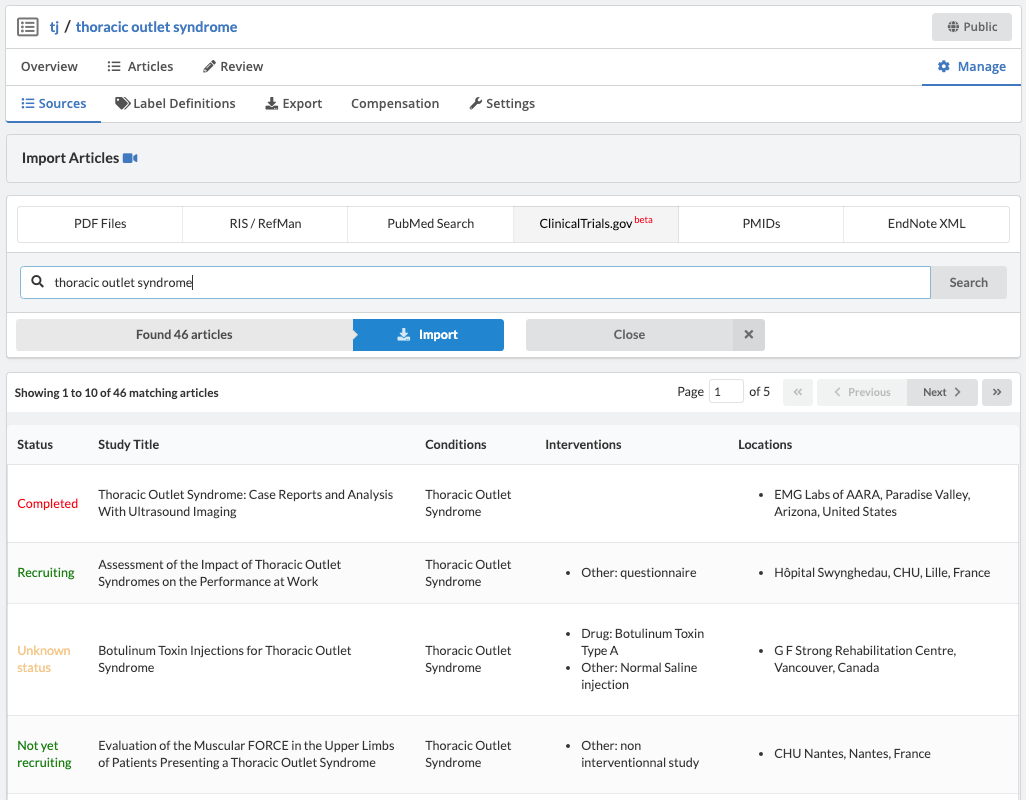
Like most partially structured sources, these documents are difficult to review. Below is the Reviewer Dashboard rendering a single trial. The hierarchical structure of the trial results in a lengthy document. Relevant information may only exist in specific fields which are difficult to locate. This is especially true as the amount of information contained in a document varies from trial to trial. Consequently, reviewing multiple trials becomes an unwieldy task - liable to result in inaccurate data.
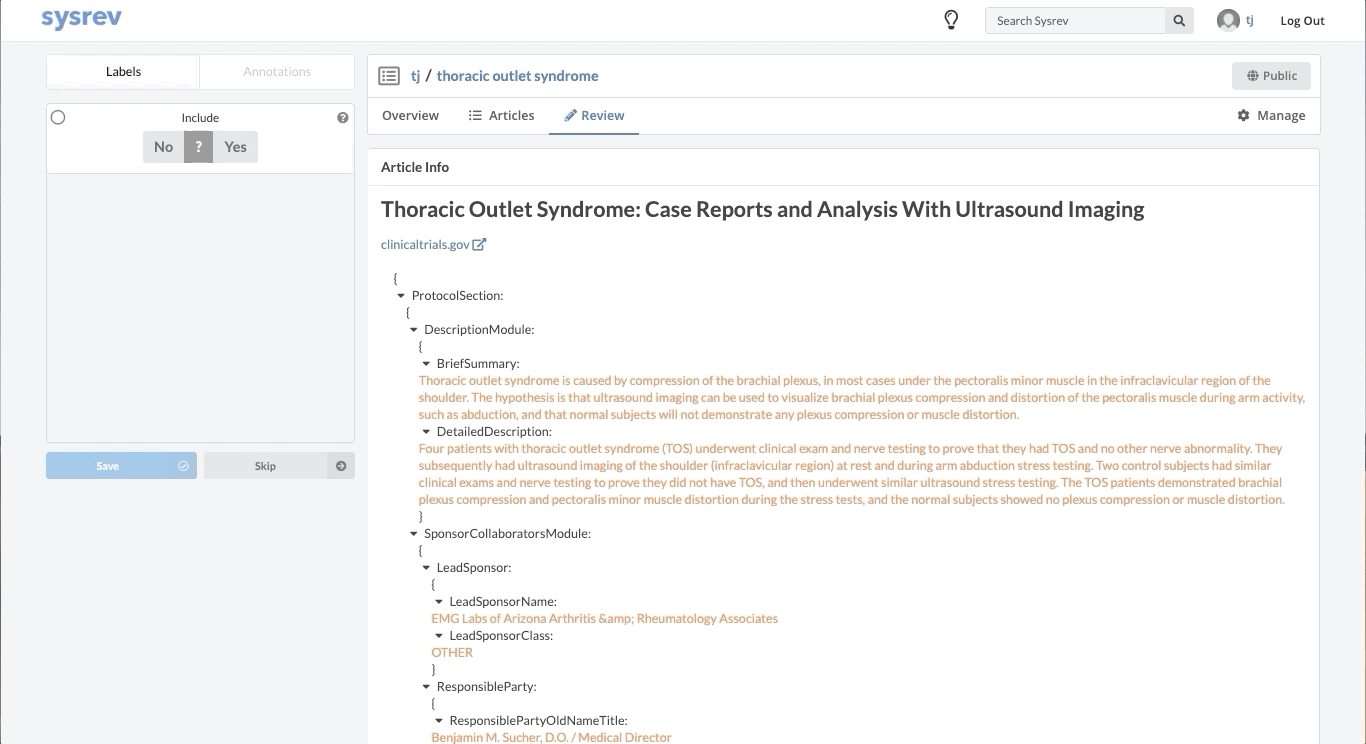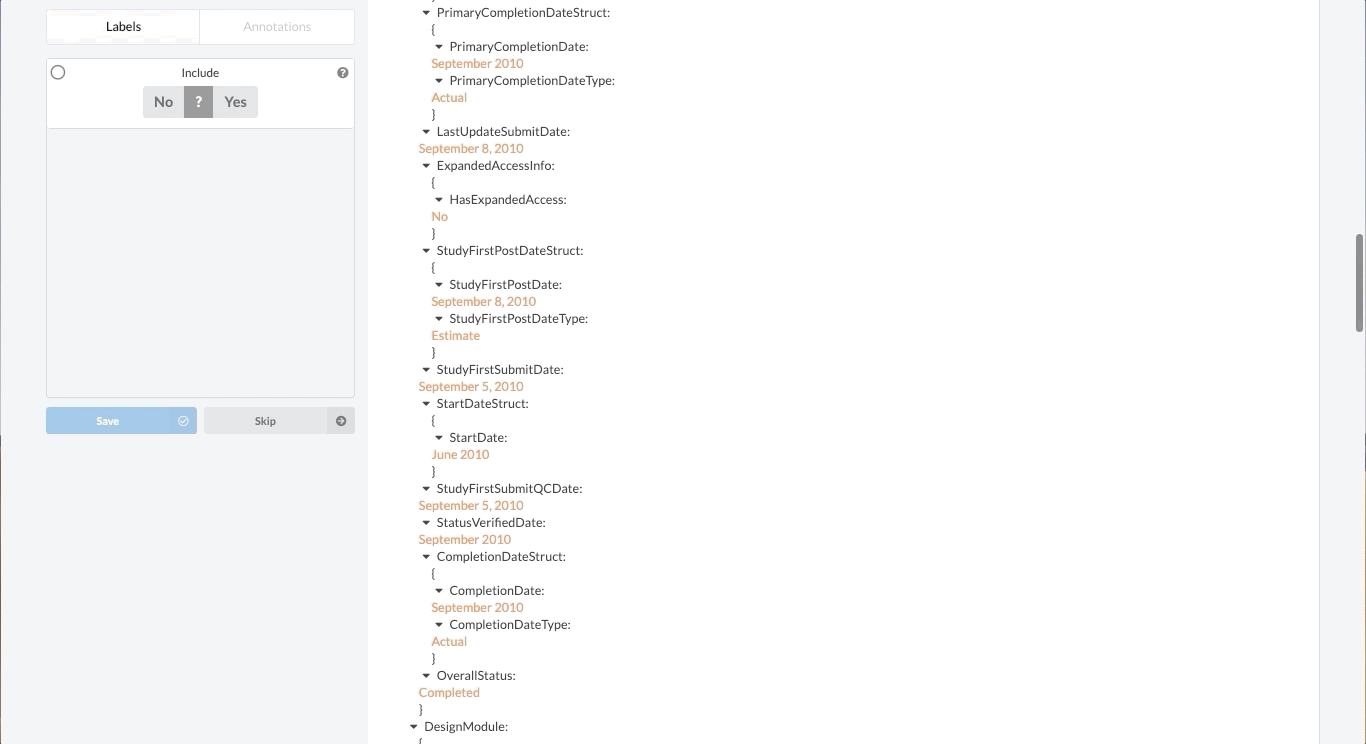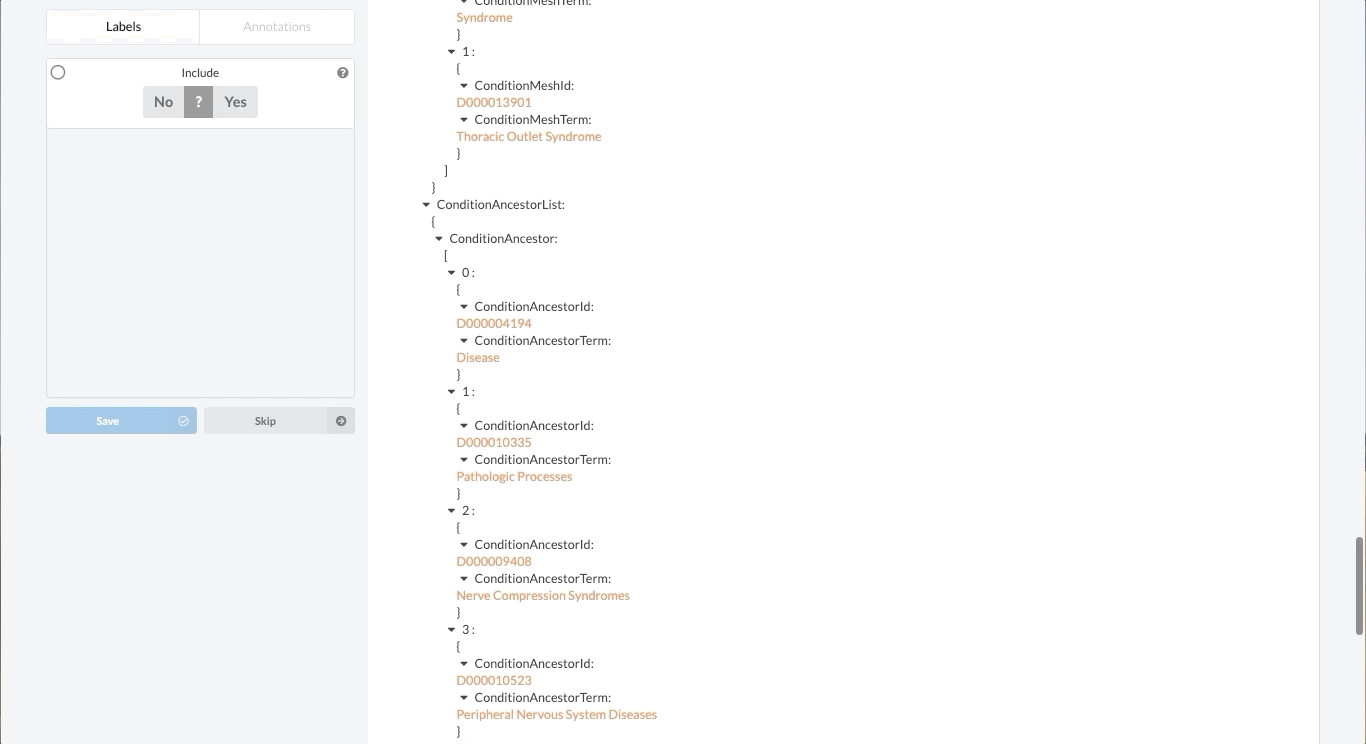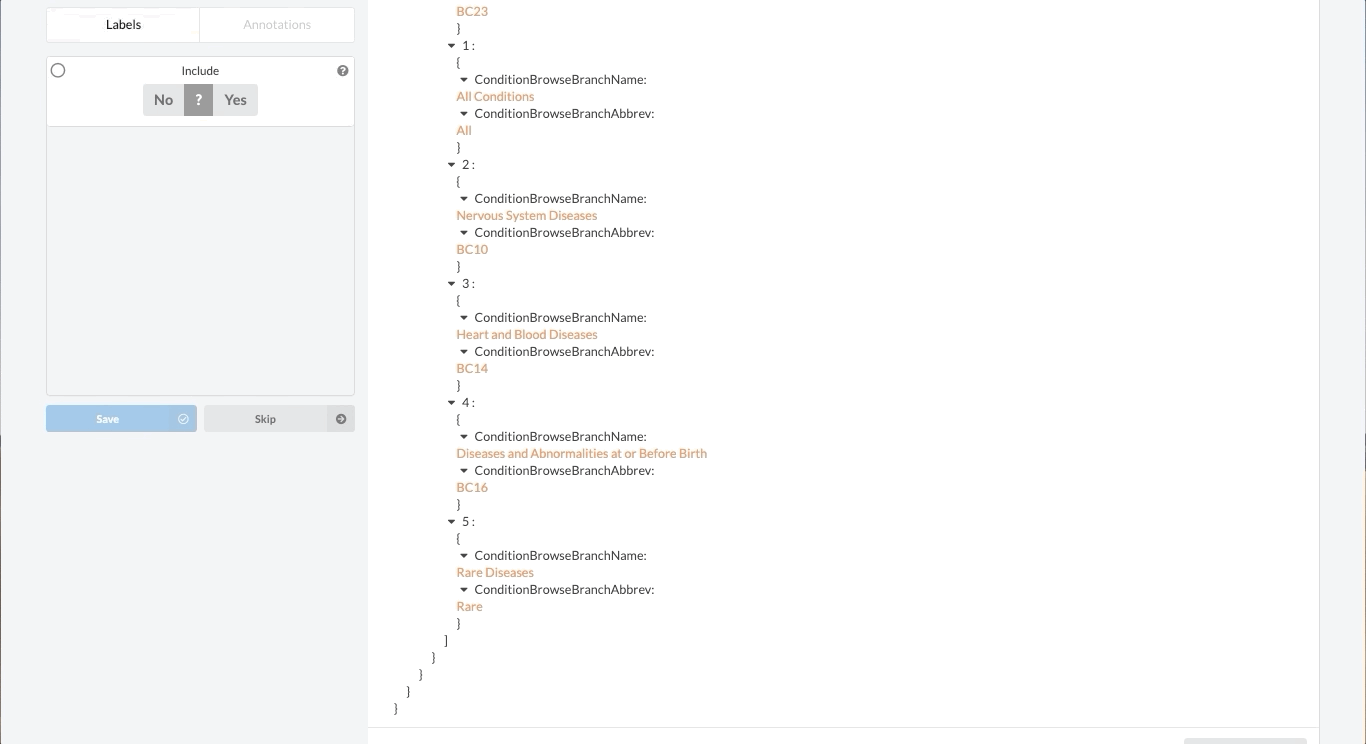
Fortunately, Sysrev has the tools to leverage the structure of the document and streamline the review. Within a given extraction project, chances are the relevant data resides in the same fields across the different documents. In our clinical trial example, perhaps we are only interested in information contained in the Brief Summary, Detailed Description, Eligibility Criteria, and demographic information. We can use Sysrev's JSON View Editor to only show those fields to reviewers.
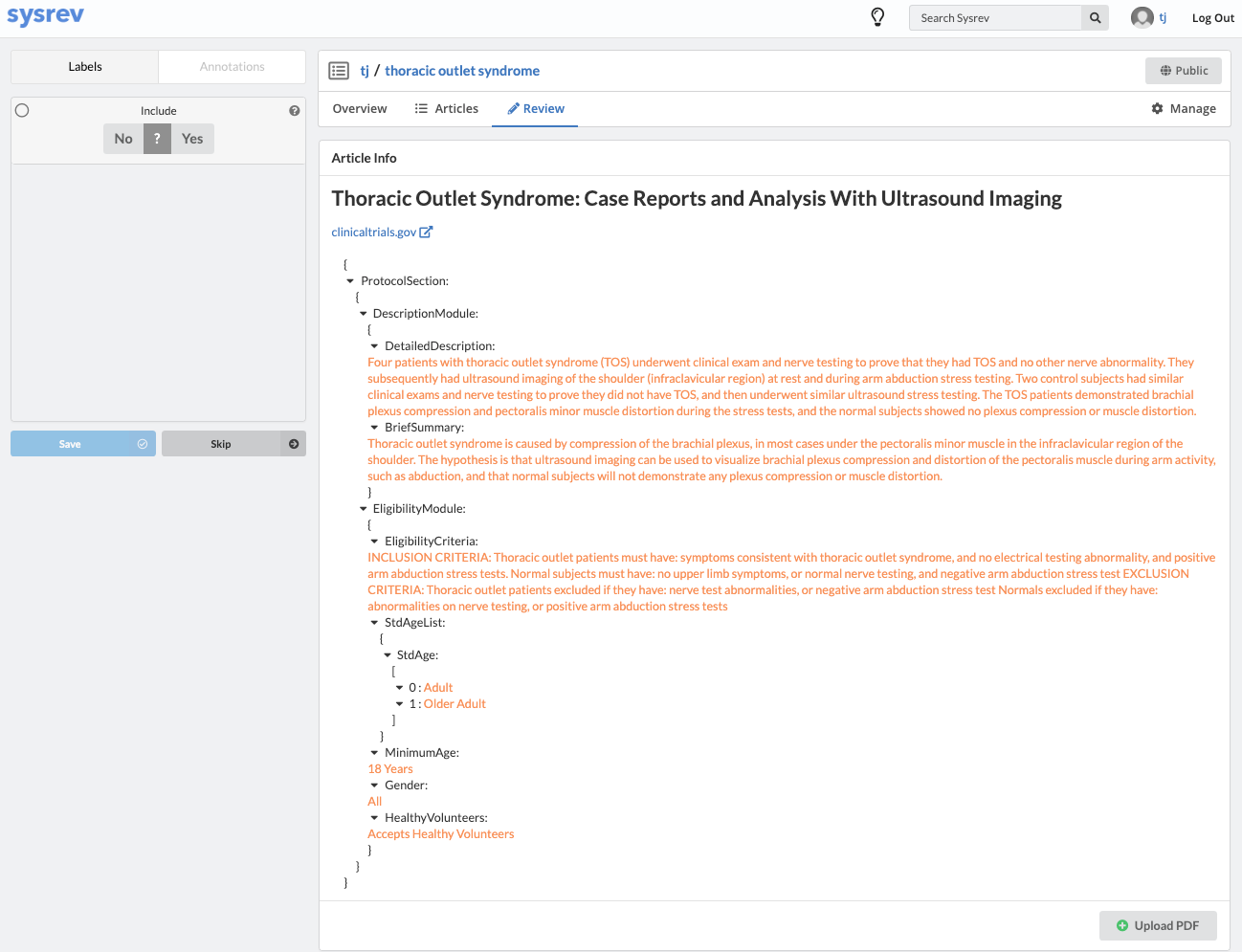
In this way, reviews of complicated documents can become easier, thereby increasing the efficiency and accuracy of reviews. Moreover, the JSON View Editor makes it simple to change which fields are shown to reviewers – giving the flexibility to conduct multiple reviews for different types of information. To see the JSON View Editor in action, check out this demo video.
The biggest untapped source of new data is partially structured documents. As Sysrev can import and customize the view of any JSON or XML document, nearly any data source can be directly reviewed from within Sysrev. To learn more about integrating and reviewing custom data sources, contact us at info@sysrev.com.